Confidence
at
merge
time
Engineers see the blast radius of their changes, before they merge — by simulating the live environment.
#6890 opened 5m ago by Platform Team · Draft
#523 opened 5m ago by Platform Team · Review required
#523 opened 5m ago by Platform Team · Closed
#112 opened 1d ago by Platform Team · Review required
#112 by Platform Team was merged just now
#6890 opened 5m ago by Platform Team · Review required
#6890 opened 5m ago by Platform Team · Draft
#523 opened 5m ago by Platform Team · Review required
#523opened 5m ago by Platform Team · Closed
#112 opened 1d ago by Platform Team · Review required
#112 by Platform Team was merged just now
Resizing a production subnet from /22 to /25 cuts available IPs from ~1,000 to 123. The api-workers autoscaling group already runs 97 instances here with a max capacity of 200. At peak traffic, new instances won't be able to launch and the service won't scale.
We investigated 3 potential risks across 32,190 resources and verified each was safe. See the investigation details below.
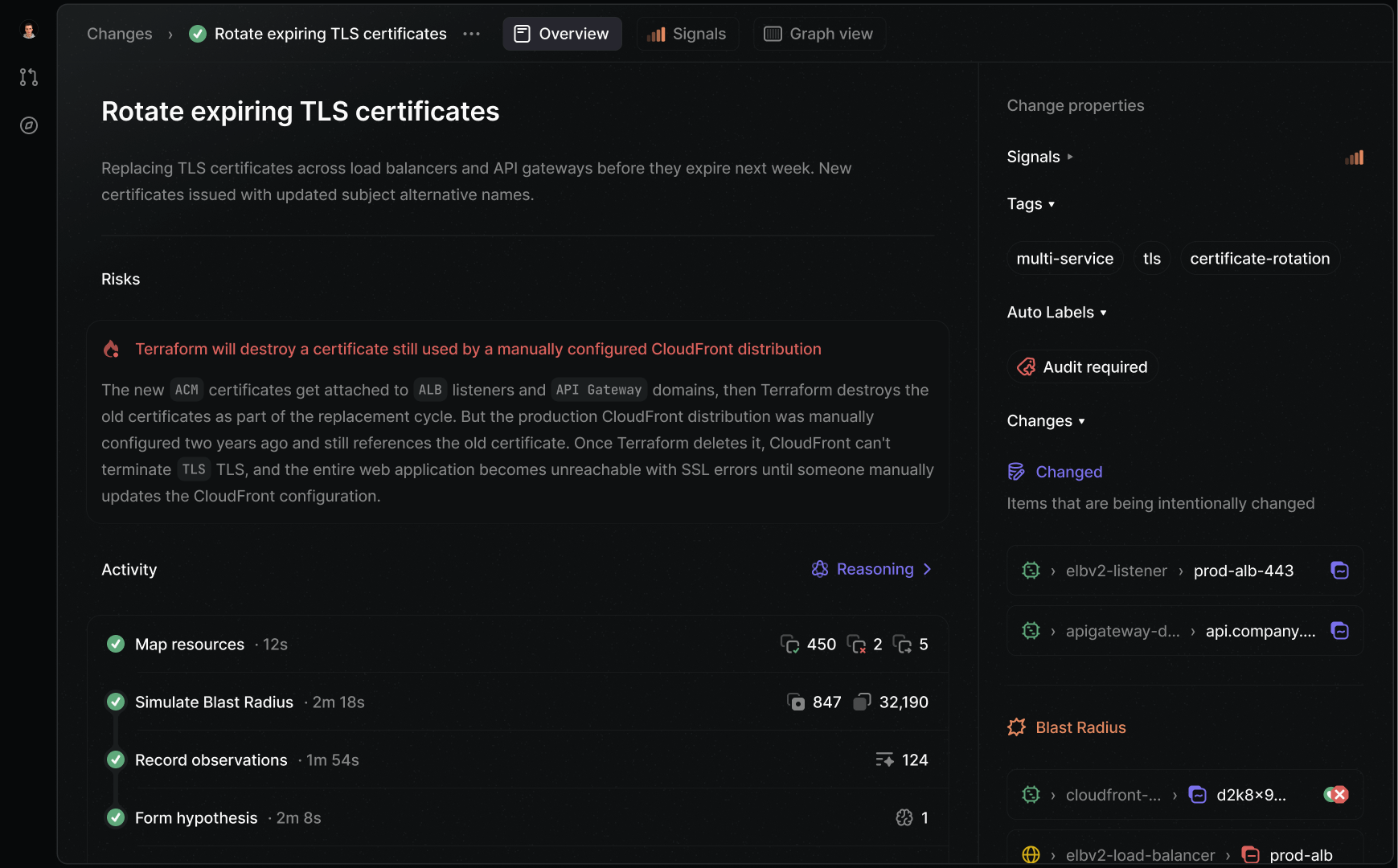
Narrowing the allowed IP range on internal-services looks like a routine security improvement — but a monitoring system in a separate VPC relies on a peering connection to health-check services behind this group. After this change, those health checks will be silently dropped, targets will be marked unhealthy, and monitoring will go dark.
Lorem ipsum dolor sit amet consectetur. Risus maecenas egestas volutpat nullam sit elit. Lorem diam facilisi non velit turpis. Id et consectetur consectetur ipsum amet commodo ut dolor in. Mi et facilisi ac consectetur tincidunt et. A turpis nisl nec arcu.
#112 opened 5m ago by Platform Team · Review required
#112 by Platform Team was merged 5m ago