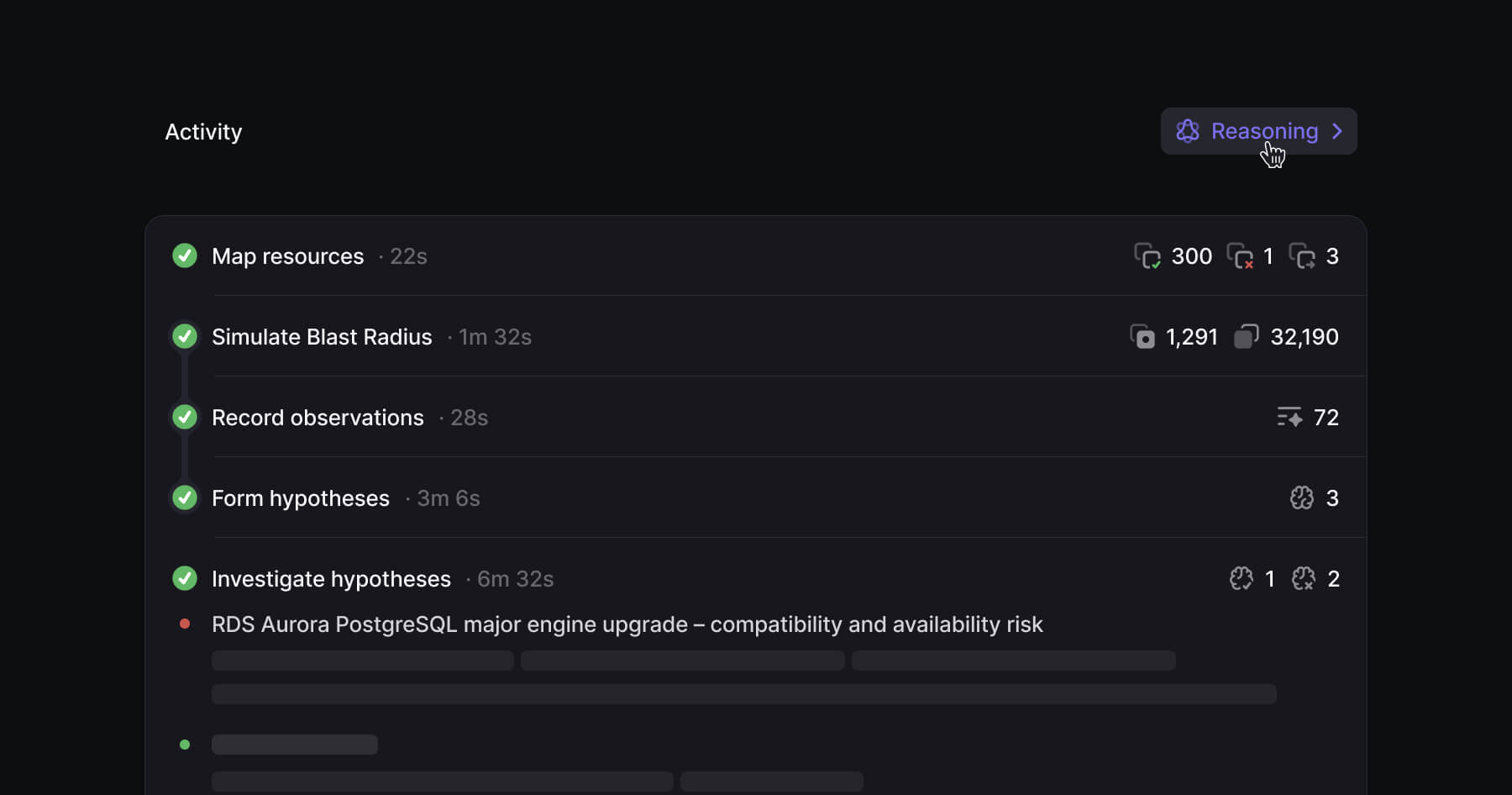
No one merges code without a security scan anymore. So why does infrastructure still ship without the full picture?
Config management, IaC, policy checks, security scanning, cost estimation, all followed the same arc. A tool emerges, early adopters prove value, a major incident accelerates demand, and within a few years the industry can't imagine deploying to prod without it. Blast radius simulation is next.