Your security group change looks innocent enough, just opening port 5432 for a new micro service. But what you don't see is that this same security group protects your production Redis cluster, your user database, and three API gateways. What should be a 5-minute change becomes a 2 hour investigation to understand the blast radius.
This scenario plays out dozens of times per week in modern engineering teams.
The 2023 State of DevOps Report shows that high-performing organisations deploy 208 times more frequently than low performers, but this velocity comes with a hidden cost, change management overhead. Teams spend up to 30% of their time on manual reviews and categorisation that could be automated.
The real problem isn't the volume of changes. It's the lack of context around those changes.
The hidden danger of "innocent" changes
That security group modification from our example illustrates a fundamental problem: infrastructure resources don't exist in isolation, but traditional change management treats them as if they do. What looks like a simple database connection update can actually be a modification to a critical network choke point that controls access to half your production services.
This happens because certain AWS resources carry disproportionate operational risk based on their role in your system architecture, not just their resource type.
A "development" RDS instance that actually serves production APIs is far more dangerous to modify than a genuinely isolated test database, even though they appear identical in the AWS console.
High-risk resources typically fall into several categories, but the key insight is that their risk level comes from their relationships, not their configuration:
- Single points of failure: That load balancer might look like standard infrastructure, but if it's the only path to your payment processing service, a misconfiguration becomes a revenue-impacting incident.
- Network choke points: Security groups, NACLs, and route tables often protect multiple services simultaneously. Change the wrong rule, and you might cut off database access for three different applications at once.
- Shared data stores: The RDS instance labeled "user-db-staging" might actually be serving production authentication requests. S3 buckets can feed data to multiple applications across different environments.
- Permission boundaries: IAM roles that look routine might actually provide access to critical resources across multiple AWS accounts. A policy change could accidentally grant or revoke access to essential services.
- Compute foundations: EKS clusters and Auto Scaling groups often run multiple applications. What appears to be a routine scaling change could affect services the modifier doesn't even know exist.
The challenge isn't just identifying these critical resources, it's understanding their true impact radius in real-time, as you're making changes. By the time you discover that your "simple" security group update affected the production Redis cluster, customer sessions are already being dropped.
Why manual reviews can be a bottleneck
Change management can create a classic scaling problem. Manual reviews become bottlenecks because only senior engineers understand which resources are truly critical.
They end up reviewing every infrastructure change, from routine port updates to production database modifications, because there's no way to automatically distinguish between high-risk and low-risk changes.
Policy-based tools struggle with context. A rule that flags "all security group changes" will treat a development sandbox update the same as a modification to your production database protection. Without understanding actual dependencies and usage patterns, these tools generate noise rather than insight. They know what changed, but not what it affects.
AWS native tools are reactive, not preventive.
Config Rules and CloudTrail provide excellent visibility into what happened after changes are applied. You can see exactly when someone modified a security group and set up alerts for certain change types. But by then, your application might already be unreachable and users are experiencing outages.
The fundamental problem is that these approaches treat infrastructure changes as isolated events rather than modifications to an interconnected system.
They either create review bottlenecks or generate false positives because they lack the context to understand which changes actually matter.
Policy-based tools like OPA can catch some issues, but they struggle with context.
A rule that flags "all security group changes" will treat a development sandbox update the same as a modification to your production database protection. Without understanding actual dependencies and usage patterns, these tools generate noise rather than insight. They know what changed, but not what it affects.
AWS Config Rules and CloudTrail provide excellent visibility into what happened after changes are applied.
You can see exactly when someone modified a security group and set up alerts for certain change types. But by then, your application might already be unreachable and users are experiencing outages.
How auto tagging can prevent incidents
Overmind's auto tagging solves the context problem by analysing infrastructure changes within your actual environment. Instead of applying rigid rules to isolated resources, it uses real-time dependency mapping to understand which changes could actually cause problems.
Real-time dependency discovery
When you run `overmind terraform plan`, the system discovers your live infrastructure and maps the relationships between resources. It identifies that your RDS instance serves three different micro services, or that a specific security group protects both your API gateway and internal databases. This means the system understands which resources are actually critical in your environment, not just which resource types are theoretically important.
The auto tagging system automatically identifies changes based on their real impact potential.
{
"name": "Production Critical Infrastructure",
"tagKey": "infrastructure_impact",
"instructions": "Analyze this Terraform change to identify if it affects AWS resources that are single points of failure or critical to production operations. Look for changes to: Application Load Balancers or Classic Load Balancers serving production traffic, NAT Gateways that are the sole internet access point for private subnets, RDS instances tagged as production or connected to production applications, Auto Scaling Groups running production workloads, or EKS clusters hosting production services. Consider the blast radius - examine which downstream resources depend on the changed resource through security group references, subnet associations, or target group memberships. Tag as 'critical' if failure would cause user-facing outages, 'high' if it would impact internal services, 'medium' for staging resources, and 'low' for development or test resources.",
"validValues": [
"critical",
"high",
"medium",
"low"
]
}
For database changes, which carry particularly high risk:
{
"name": "Database Impact Assessment",
"tagKey": "database_risk",
"instructions": "Evaluate if this change affects AWS database resources including RDS instances, RDS clusters, DynamoDB tables, ElastiCache clusters, or their associated security groups, parameter groups, and subnet groups. Analyze the blast radius to determine which applications connect to these databases by examining security group rules, Lambda function VPC configurations, and EC2 instances in the same subnets. Check resource tags and naming conventions to distinguish between environments (prod, staging, dev). Flag as 'production_db' if the database serves production applications, 'staging_db' for pre-production testing, 'dev_db' for development work. Use 'backup_config' for changes to backup retention, automated backups, or snapshot configurations. Use 'network_config' for security group, subnet group, or VPC changes that affect database connectivity.",
"validValues": [
"production_db",
"staging_db",
"dev_db",
"backup_config",
"network_config"
]
}
For network modifications that could instantly cut off access:
{
"name": "Network Security Risk",
"tagKey": "network_impact",
"instructions": "Assess if this change modifies AWS network security configurations that could affect service connectivity or expose resources inappropriately. Examine changes to Security Groups (ingress/egress rules, especially 0.0.0.0/0 or ::/0 sources), NACLs (Network Access Control Lists), Route Tables (especially default routes or routes to Internet Gateways), VPC configurations (CIDR blocks, peering connections), or Internet Gateways and NAT Gateways. Analyze the blast radius by identifying which EC2 instances, RDS instances, Load Balancers, or other services are protected by these network controls. Tag as 'connectivity_risk' if changes could break existing service connections, 'exposure_risk' if changes could inappropriately expose services to the internet or unintended networks, 'routing_change' for modifications that alter traffic paths, and 'low_impact' for changes to development resources or non-critical network segments.",
"validValues": [
"connectivity_risk",
"exposure_risk",
"routing_change",
"low_impact"
]
}
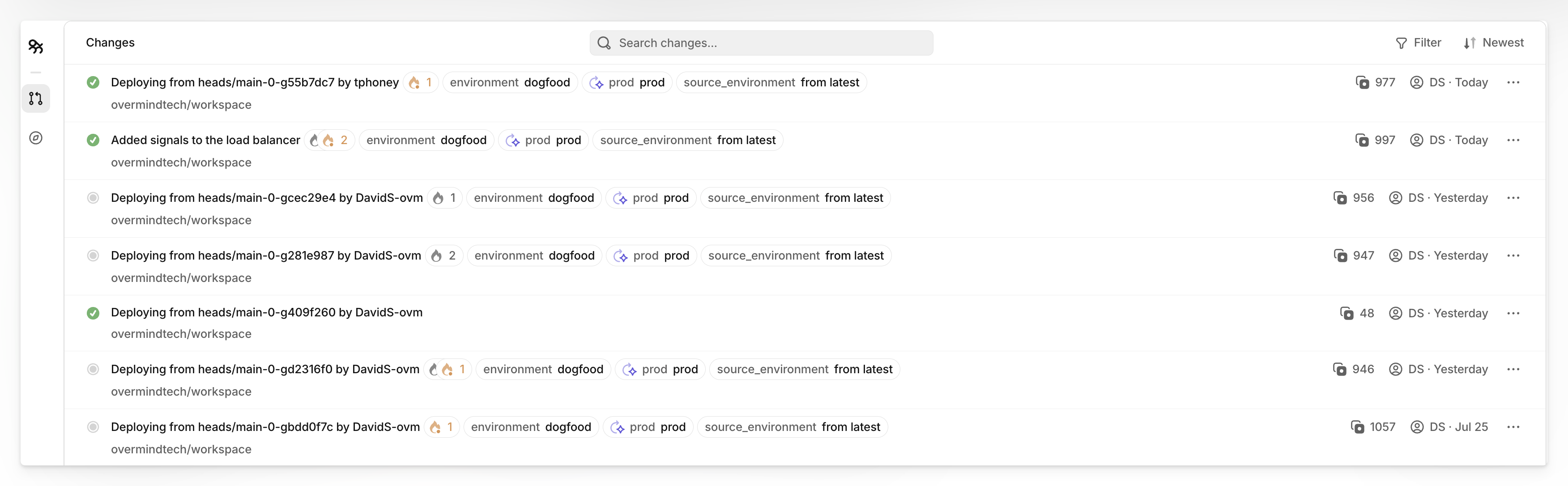
Back to our security group example: A developer updates a security group to allow a new micro service database connection.
Traditional tools see a port change. Overmind's auto tagging maps the dependencies, identifies that this security group also protects the Redis cluster used for session storage, flags the change as affecting critical infrastructure, and provides specific context about the potential blast radius.
The developer gets immediate feedback about what could be impacted. Reviewers can focus their attention on changes that actually matter. Routine updates proceed without bottlenecks.
Smart auto tagging creates a culture where teams can move fast on safe changes while being appropriately careful with risky modifications.
Routine updates get tagged as low-risk and proceed with minimal review. Changes that look simple but affect critical resources get flagged for additional scrutiny. Instead of cryptic policy violations, teams get plain English explanations of potential impact
The goal isn't to prevent all changes, it's to ensure that high-risk changes get appropriate attention while routine updates don't slow down development velocity.
Getting started
Start by mapping the AWS resources that would cause user-facing outages if they became unavailable. Navigate to Settings > Configuration > Auto Tagging in the Overmind web application and create your first rule targeting these high-impact areas.
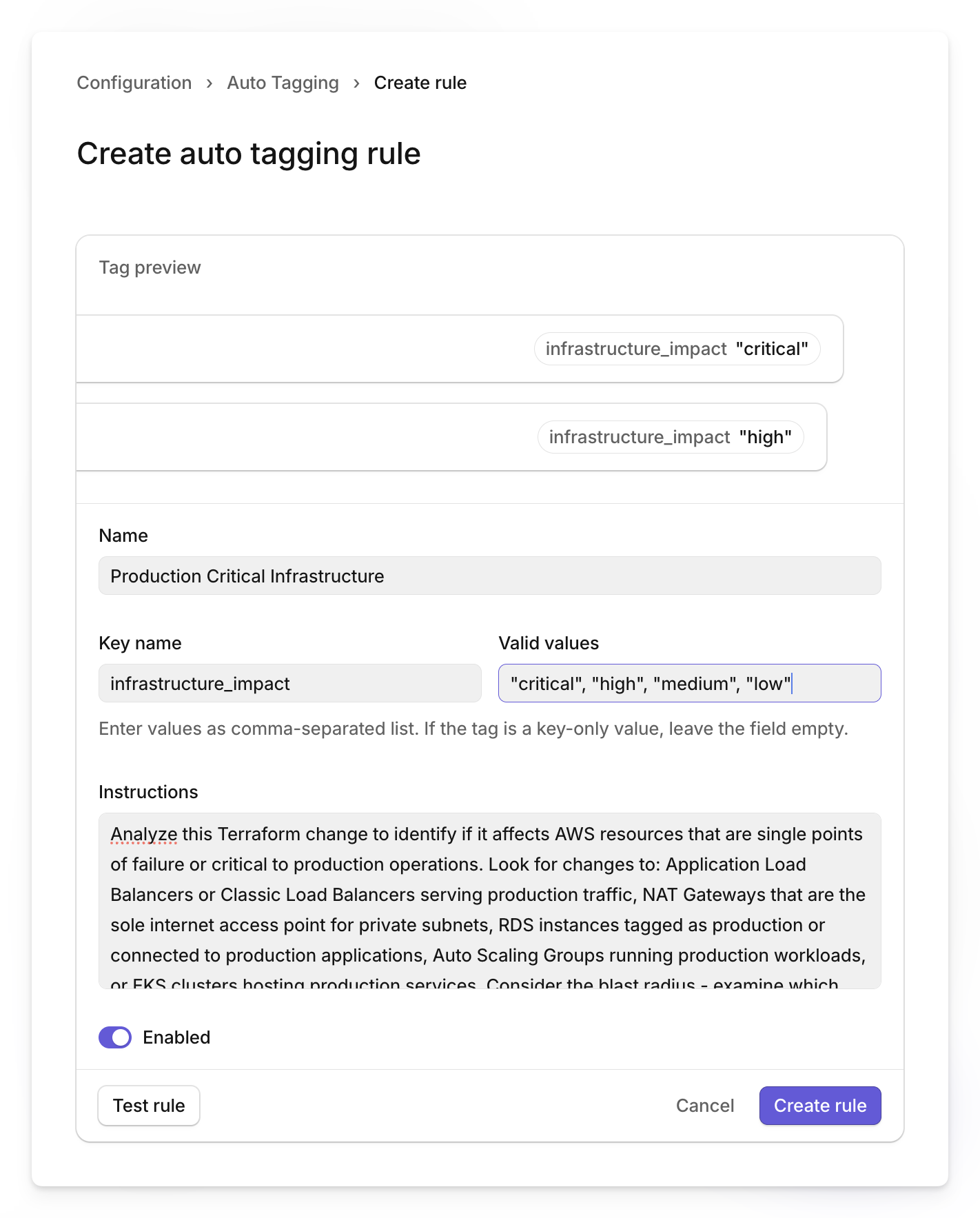
When creating a new rule, you'll need to fill out several key fields.
- Provide a descriptive Name and unique Key name that will appear on tagged changes.
- Enter comma-separated Valid values like "critical", "high", "medium", "low" for the AI to assign.
- The Instructions field is most important - specify which AWS resource types to monitor, what makes changes high-risk, and how to distinguish impact levels.
Before deploying your rules, validate they catch the right scenarios using the testing functionality.
Choose 5-10 changes from your change history, including both routine updates and changes that caused past incidents.
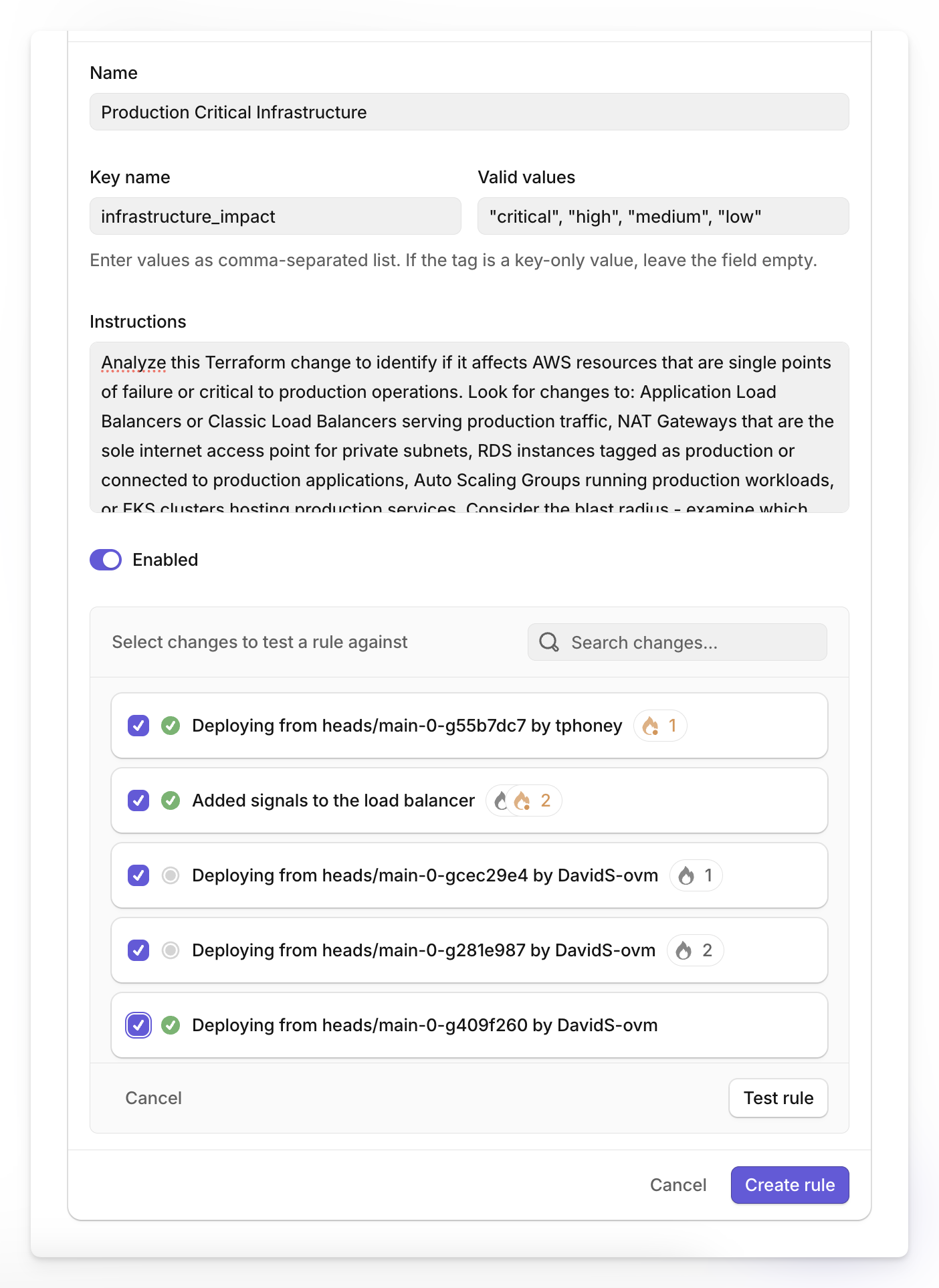
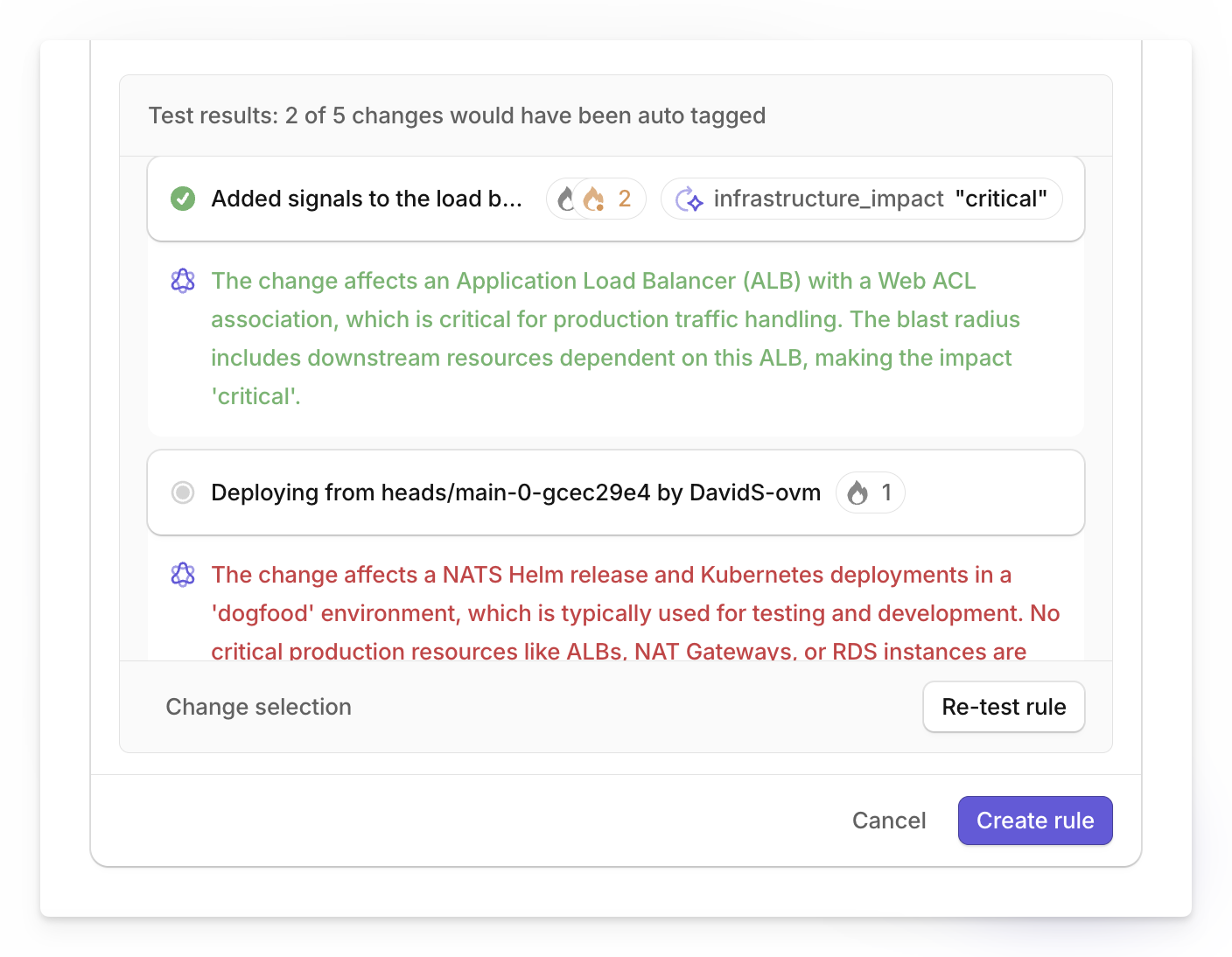
Click the test button for each rule and run it against your selected changes, then examine whether the rule correctly identifies high-risk changes and avoids false positives on routine updates.
Based on the test results, adjust the rule's instructions if it's missing critical changes or flagging too many routine ones. This testing process ensures your rules will perform accurately when applied to future infrastructure changes.
Ready to stop fearing your infrastructure changes? Try Overmind's auto tagging and see which of your changes are actually high-risk.