When Boeing's 737 MAX aircraft suffered two fatal crashes killing 346 people, the world discovered a chilling truth: software that passes automated tests can still fail catastrophically in the real world. The Maneuvering Characteristics Augmentation System (MCAS) had successfully completed Boeing's test scenarios but contained a fatal flaw—it relied on input from a single angle-of-attack sensor without redundancy or pilot override capability. When faulty sensors triggered the system during flight, MCAS repeatedly pushed the aircraft's nose down despite pilot attempts to regain control. This testing gap cost Boeing over $20 billion in grounding costs, compensation, legal settlements, and lost orders, while destroying public trust in aviation safety systems.
The software testing crisis extends far beyond isolated incidents. Industry data reveals that 75% of companies still lack full test automation, while developers spend approximately 30% of their time on manual testing activities. The GitLab DevSecOps Survey identifies testing as the number one cause of deployment delays for the third consecutive year. IBM's Systems Science Institute research demonstrates why these testing gaps prove so costly: bugs found in production cost 100 times more to fix than those caught during design phase, with the National Institute of Standards and Technology confirming a 30x cost multiplier for production defects versus early development issues.
Cloud infrastructure failures demonstrate how testing gaps cascade through interconnected systems. Microsoft Azure's leap year bug on February 29, 2012, caused a 10-13 hour global outage when the Guest Agent calculated certificate expiration dates by simply adding one year, creating an invalid date that crashed the entire certificate creation process. Microsoft later admitted in their post-mortem: "We are taking steps that improve our testing to detect time-related bugs." The TSB Bank's 2018 IT migration disaster cost £330 million and affected 1.9 million customers for weeks due to inadequate data migration testing between platforms, ultimately leading to the CEO's resignation and mass customer exodus.
Meanwhile, AI promises to revolutionize software testing through automated test generation, intelligent failure analysis, and self-healing test suites. Yet teams struggle to evaluate which AI testing tools deliver genuine value versus creating new categories of risk. The question isn't whether AI testing works—it's understanding when these tools create confidence versus when they create catastrophic blind spots.
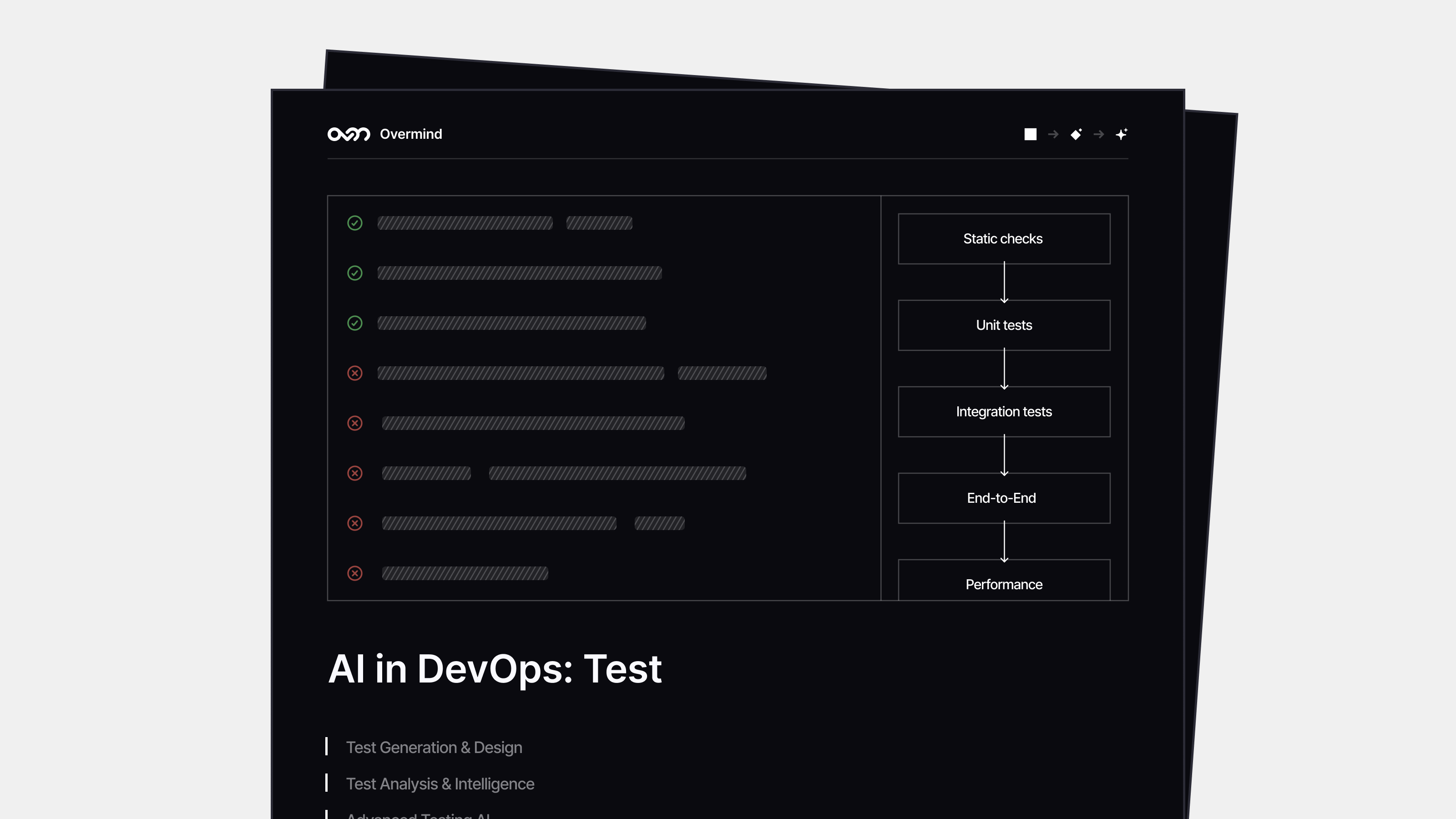
Use Case #1: AI-Powered Test Case Generation and Suggestions
Description: AI analyzes existing code, requirements documents, and test suites to generate comprehensive test case suggestions. The system identifies edge cases, boundary conditions, and integration scenarios, presenting recommendations through IDE interfaces or testing platforms that developers review and approve before implementation.
Current Pain Point: Test case creation consumes massive developer time while often missing critical edge cases. Teams spend 30% of development cycles writing tests manually, with junior developers struggling to identify comprehensive test scenarios. Industry research shows that 60% of organizations report test cases are not well-written and maintained, while 42% of testers don't feel comfortable writing automation scripts.
Success Scenario: AI generates comprehensive test cases covering edge cases human developers typically miss, dramatically reducing test creation time while improving coverage. Teams achieve both higher velocity and better quality through AI-assisted test generation that identifies scenarios like the Toyota race condition or Boeing sensor failure modes.
Failure Scenario: AI suggests poor-quality tests that pass code review but provide false confidence, missing critical bugs that reach production. Developers become over-reliant on AI suggestions and stop thinking critically about edge cases, leading to systematic blind spots in test coverage.
CAIR Evaluation
- Value of Success 4/5: Diffblue Cover achieves 26x faster unit test creation; AWS automotive testing shows 80% time reduction; QMetry reduces effort from 45 minutes to seconds
- Perceived Risk 1/5: Suggestions only with human review; no automatic execution; operates in safe development environment with no production impact
- Effort to Correct 1/5: Simple to reject or modify suggestions; instant feedback loop; no rollback procedures needed
CAIR Calculation: 4 ÷ (1 × 1) = 4.0
Priority Level: High Priority (CAIR > 3)
Use Case #2: Automated Flaky Test Detection and Analysis
Description: AI monitors test execution patterns across builds to identify flaky tests, calculate flakiness probability scores, and predict which tests are likely to fail due to environmental factors rather than code issues. The system provides recommendations for test stabilization while maintaining human approval for all test suppression decisions.
Current Pain Point: Flaky tests undermine confidence in CI/CD pipelines and consume significant engineering time. Google reports that 1.5% of all test runs exhibit flaky behavior, affecting 16% of all tests. Manual test failure investigation consumes approximately 28 minutes per incident, with teams struggling to distinguish between genuine regressions and environmental issues.
Success Scenario: AI accurately identifies flaky tests before they disrupt development workflows, automatically quarantining unreliable tests while flagging legitimate failures. Teams maintain high confidence in their test suites while reducing manual triage overhead and improving deployment velocity.
Failure Scenario: AI incorrectly classifies genuine test failures as flaky behavior, causing real bugs to be suppressed and reach production. Conversely, AI may flag stable tests as flaky due to temporary environmental issues, reducing effective test coverage when reliable tests are unnecessarily quarantined.
CAIR Evaluation
- Value of Success 4/5: Meta's system doubles testing infrastructure efficiency; Slack improved stability from 20% to 96%; saves 553 hours monthly of manual triage
- Perceived Risk 3/5: False positives can hide real bugs reaching production; false negatives waste significant engineering time on spurious failures
- Effort to Correct 3/5: Requires investigation to validate AI classifications; need to establish override processes; debugging misclassified tests takes significant effort
CAIR Calculation: 4 ÷ (3 × 3) = 0.44
Priority Level: Medium Priority (CAIR 1-3)
Use Case #3: Autonomous Test Execution and Self-Healing
Description: AI automatically generates, executes, and maintains test suites with minimal human intervention. The system self-heals broken test scripts by updating locators, adapting to UI changes, and generating new test cases for modified functionality. AI reports test results autonomously and may integrate with deployment pipelines for automated go/no-go decisions.
Current Pain Point: Manual test maintenance consumes significant resources as applications evolve. UI changes break automated tests, requiring constant developer attention to update selectors and workflows. Teams want to eliminate manual test maintenance overhead while ensuring comprehensive coverage of new functionality.
Success Scenario: Fully autonomous testing that adapts to application changes, maintains comprehensive coverage, and provides reliable quality gates without human intervention. Development velocity increases dramatically as teams focus on feature development rather than test maintenance.
Failure Scenario: Self-healing tests adapt to broken functionality rather than reporting failures, masking genuine regressions and bugs. AI generates false confidence through tests that pass when they should fail, creating systematic blind spots that allow critical issues to reach production undetected.
CAIR Evaluation
- Value of Success 5/5: Complete automation eliminates manual test maintenance; 80% faster execution; 90% reduction in test script maintenance overhead
- Perceived Risk 5/5: Replit database deletion; Tesla Autopilot 736+ accidents; Boeing 737 MAX 346 deaths; COVID AI diagnostics failed clinical validation
- Effort to Correct 4/5: Complex debugging of AI decisions; 3-5x longer investigation time; cascading failures difficult to trace and fix
CAIR Calculation: 5 ÷ (5 × 4) = 0.25
Priority Level: Low Priority (CAIR < 1)
CAIR Priority Levels
- High Priority (CAIR > 3): Invest immediately
- Medium Priority (CAIR 1-3): Pilot carefully with safety measures
- Low Priority (CAIR < 1): Avoid or delay until you can improve the score
The testing stage reveals a critical pattern: AI excels at augmenting human testing capabilities but fails catastrophically when operating autonomously in high-stakes environments. Test case generation scored highest because it provides suggestions in safe development environments where mistakes have no production impact. Flaky test detection offers value but requires validation since false classifications can hide real bugs or waste engineering time. Autonomous testing scored lowest due to documented catastrophic failures when AI systems operate without human oversight.
Remember Microsoft Azure's leap year bug? Their systems passed all automated tests, the engineering team had confidence in their deployment process, yet a simple date calculation error caused a global 10-13 hour outage affecting millions of users. The testing had covered normal scenarios but missed the edge case that brought down the entire platform.
This pattern—confident testing that misses critical failure modes—repeats across AI testing tools. The companies succeeding with AI testing understand the difference between AI as a powerful productivity multiplier versus AI as an autonomous decision-maker. Test case generation with human review delivers 26x productivity gains safely. Autonomous systems promise efficiency but create blind spots that compound until they cause major incidents.
Your CAIR analysis should guide where you invest your AI testing budget. High CAIR tools like test case generation provide immediate value with minimal downside. Low CAIR autonomous systems require you to bet your reliability on AI edge case handling. The framework helps you distinguish between genuine productivity opportunities and expensive distractions disguised as innovation.
References
- Boeing. "737 MAX Updates." Boeing Commercial Airplanes, 2024. https://www.boeing.com/737-max-updates/
- Consortium for Information & Software Quality. "The Cost of Poor Software Quality in the US: A 2022 Report." 2022. https://www.it-cisq.org/the-cost-of-poor-quality-software-in-the-us-a-2022-report/
- GitLab. "2024 Global DevSecOps Report." 2024. https://about.gitlab.com/developer-survey/
- IBM Systems Science Institute. "The Economic Impacts of Inadequate Infrastructure for Software Testing." Referenced for 100x cost multiplier of production bugs. https://www.functionize.com/blog/the-cost-of-finding-bugs-later-in-the-sdlc
- National Institute of Standards and Technology. "Software Errors Cost U.S. Economy $59.5 Billion Annually." 2002. https://www.nist.gov/news-events/news/2010/11/updated-nist-software-uses-combination-testing-catch-bugs-fast-and-easy
- Toyota Motor Corporation. "2009–2011 Toyota vehicle recalls." Wikipedia, 2025. https://en.wikipedia.org/wiki/2009–2011_Toyota_vehicle_recalls
- European Space Agency. "Ariane 501 Flight Failure Report." 1996. $370 million payload loss details.
- Microsoft Azure. "Summary of Windows Azure Service Disruption on Feb 29th, 2012." Azure Blog, 2012. https://azure.microsoft.com/en-us/blog/summary-of-windows-azure-service-disruption-on-feb-29th-2012/
- TSB Bank. "IT Migration Programme Independent Report." 2018. £330 million cost and customer impact figures.
- Diffblue. "Diffblue Cover and GitHub Copilot: A study comparing speed, reliability and accuracy." 2025. https://www.diffblue.com/resources/diffblue-cover-and-github-copilot-a-study-comparing-speed-reliability-and-accuracy/
- AWS. "Using generative AI to create test cases for software requirements." Amazon Web Services Blog, 2024. https://aws.amazon.com/blogs/industries/using-generative-ai-to-create-test-cases-for-software-requirements/
- QMetry. "AI-Powered Test Case Generation Results." SmartBear Blog, 2024. https://smartbear.com/blog/from-hours-to-seconds-how-qmetry-uses-ai-to-redefine-test-case-creation/
- Meta Engineering. "Predictive test selection to ensure reliable code changes." Engineering at Meta Blog, 2018. https://engineering.fb.com/2018/11/21/developer-tools/predictive-test-selection/
- Meta Engineering. "Probabilistic flakiness: How do you test your tests?" Engineering at Meta Blog, 2020. https://engineering.fb.com/2020/12/10/developer-tools/probabilistic-flakiness/
- Slack Engineering. "Handling Flaky Tests at Scale: Auto Detection & Suppression." Engineering at Slack Blog, 2021. https://slack.engineering/handling-flaky-tests-at-scale-auto-detection-suppression/
- Google Testing Blog. "Flaky Tests at Google and How We Mitigate Them." 2016. https://testing.googleblog.com/2016/05/flaky-tests-at-google-and-how-we.html
- Fortune. "AI-powered coding tool wiped out a software company's database in 'catastrophic failure'." 2025. https://fortune.com/2025/07/23/ai-coding-tool-replit-wiped-database-called-it-a-catastrophic-failure/
- NPR. "Jury orders Tesla to pay more than $240 million in Autopilot crash." 2025. https://www.npr.org/2025/08/02/nx-s1-5490930/tesla-autopilot-crash-jury-240-million-florida
- Federal Aviation Administration. "Summary of the FAA's Review of the Boeing 737 MAX." 2022. https://www.faa.gov/sites/faa.gov/files/2022-08/737_RTS_Summary.pdf
- MIT Technology Review. "Hundreds of AI tools have been built to catch covid. None of them helped." 2021. https://www.technologyreview.com/2021/07/30/1030329/machine-learning-ai-failed-covid-hospital-diagnosis-pandemic/