Every few years, a infrastructure practice goes from 'nice to have' to 'how did we ever ship without this?'. Config management, IaC, policy checks, security scanning, cost estimation, all followed the same arc. A tool emerges, early adopters prove value, a major incident accelerates demand, and within a few years the industry can't imagine deploying to prod without it. Blast radius simulation is next.
Learning from the past
Most notably the pattern is compressing, each successive practice reaches mainstream adoption faster than the last. Policy-as-code went from CNCF Sandbox to graduated in 36 months. Infracost reached 10% Fortune 500 adoption in four years. The industry learns faster now. The complexity is worse, the incidents are more expensive, and platform teams spread practices faster than ever.
When IaC first emerged, "complex" meant managing dozens of resources. Now it means millions, spread across clouds, regions, and accounts. HashiCorp's 2024 data shows only 8% of organisations qualify as "highly cloud mature." That's not a criticism of anyone, it's the reality of operating at a scale the original tooling wasn't designed for.
DORA's research tells a similar story. Elite performers deploy on-demand with change failure rates under 5%, but only around 19% of organisations reach elite performance and the high-performance cluster actually shrank from 31% to 22% between 2023 and 2024. The gap isn't about effort or intelligence. It's about what's possible with the tools available and the constraints teams operate under.
What we are hearing
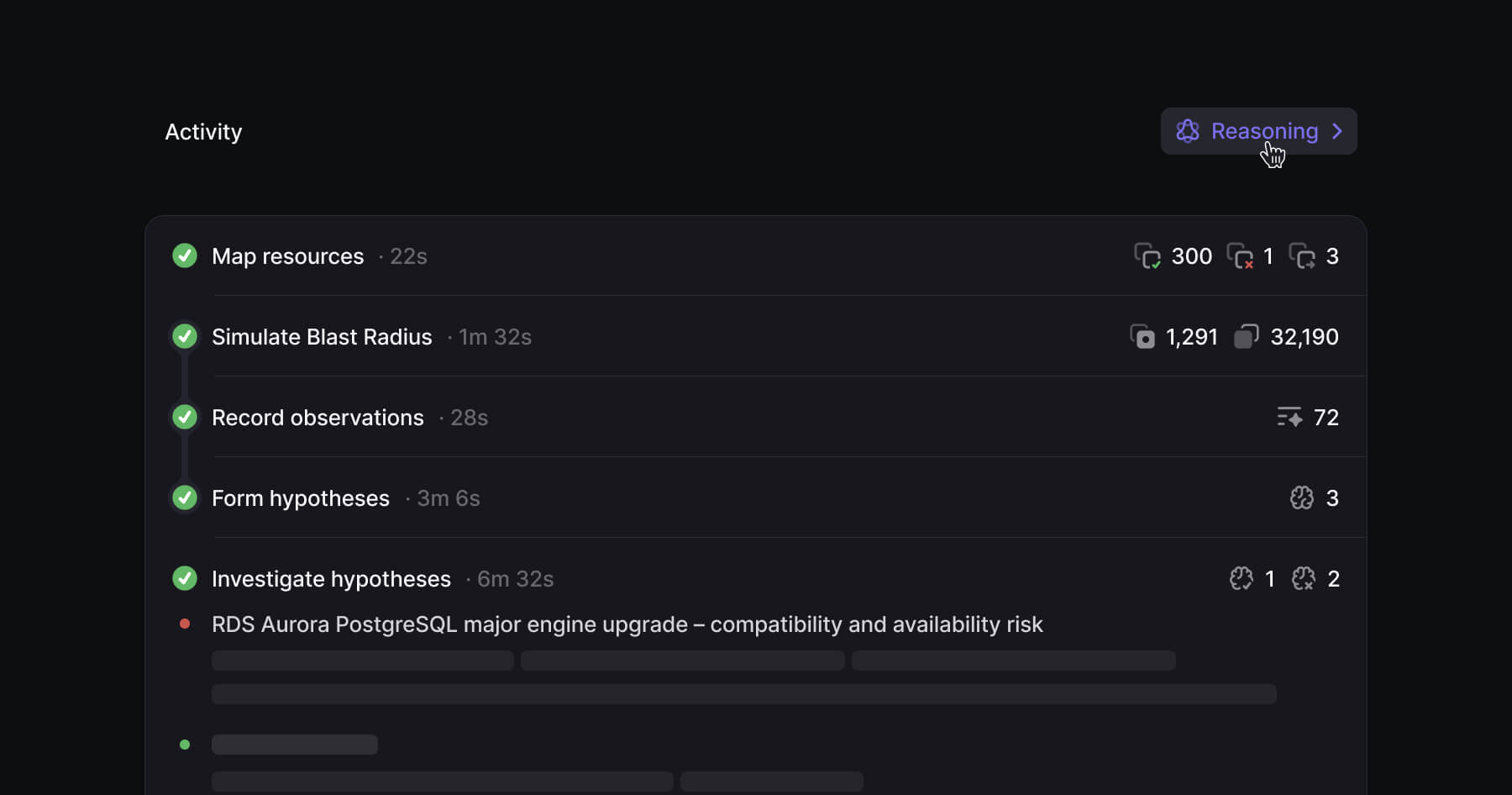
We talk to platform teams every week, and the same things are front of mind. The plan shows what's changing - 3 added, 2 modified, 1 destroyed but it doesn't show what depends on those resources. What loses connectivity. What breaks downstream. What pages someone at 2am.
That context exists somewhere. It's in someone's head, in tribal knowledge, in the engineer who's been there five years and just knows how everything connects. But it's not in the tooling. So reviews become bottlenecks, senior engineers get pulled into every change, and new starters can't ship with confidence because they don't have the mental model yet.
This isn't because anyone did something wrong. The tooling to surface this context simply didn't exist. You can't adopt what isn't there.
Why now
The way your peers write applications has changed (I don't need to mention the two letter word behind a lot of this..) Idea to shipping code is now measured in hours, not weeks. That means infrastructure pipelines need to keep pace. But review bottlenecks, single-threaded state files, and the "let me check with someone who knows" workflow weren't built for this speed.
I'm not saying to throw it all out. The status quo is the status quo because it works. It wasn't an accident, and the people who built it weren't misguided. But the context is different now.
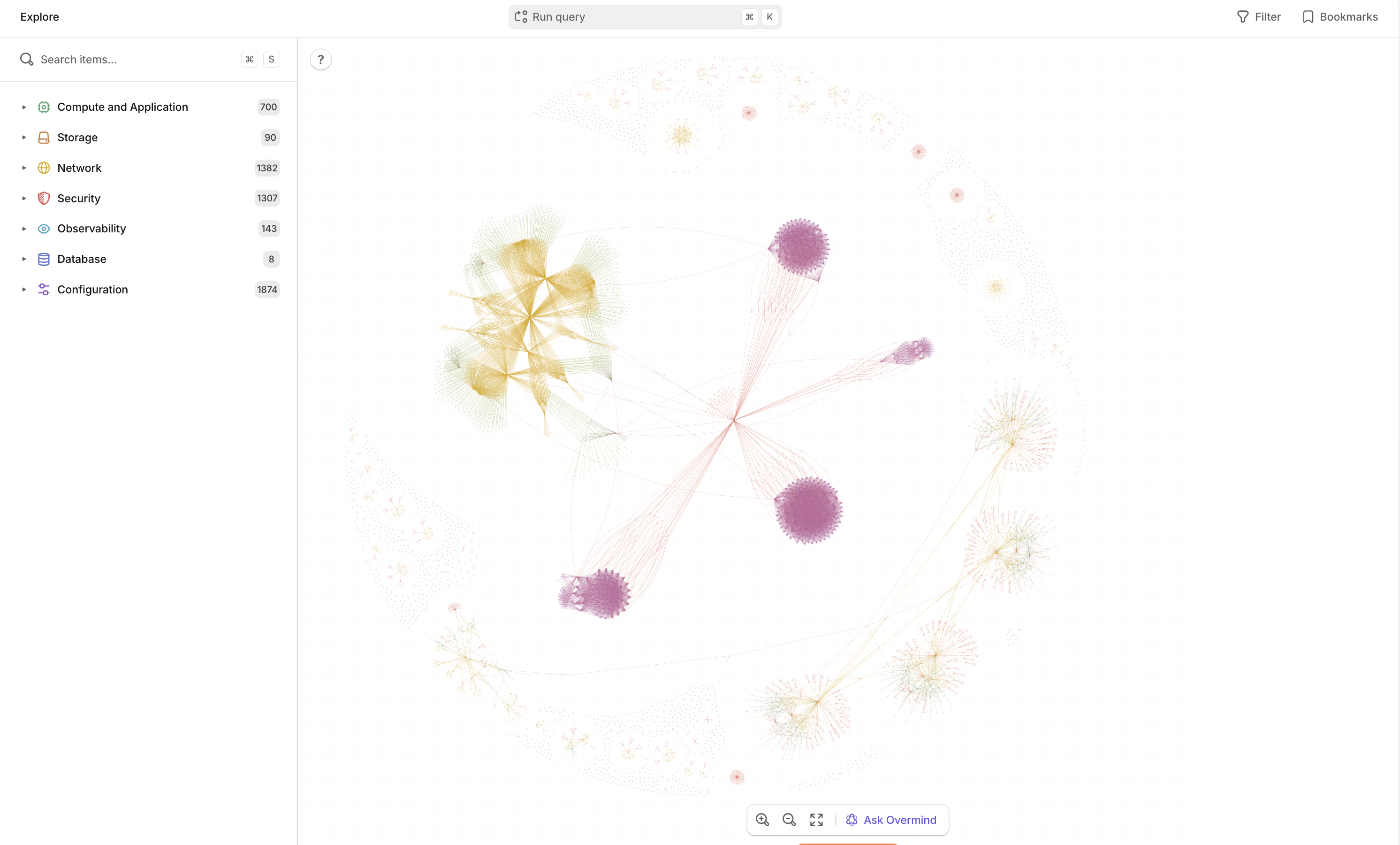
Cloud providers expose more relationship data than they used to. Graph databases make dependency modelling possible at scale. The "shift left" pattern is moving checks earlier in the pipeline. Teams are starting to ask a reasonable question: if we can check for security misconfigurations before merge, and estimate cost before merge, why can't we see blast radius before merge?
Some leading teams from the likes of Netflix and others are building internal tooling for this. Some are adopting early-stage products. Some are waiting to see what matures. All of those are valid choices.
Our approach
Overmind discovers hidden dependencies from your live environment and surfaces the context that usually lives in someone's head. We simulate every change against live infrastructure data and show you the blast radius, the risks, and what's affected right in the PR comment, where the review happens.
We're not saying everyone needs this today. We're saying the teams we talk to are asking for it, and if the pattern holds, more will follow.
Take what's useful
If reviews are a bottleneck for your team, this might help. If senior engineers get pulled into every infrastructure change because they're the only ones who understand the dependencies, this might help. If you're shipping at a pace where manual review can't keep up, this might help.
If your current setup is working, keep doing what you're doing. The status quo exists because it solved real problems for real teams. We're not here to tell anyone they're behind or doing it wrong.
We're just sharing what we're seeing, what we're hearing, and what we're building as a result. Take what's useful. Leave the rest. And have empathy for everyone including the people who look at all this and decide it's not for them.